BanglaBias
Read Between the Lines: A Benchmark for Uncovering Political Bias in Bangla News Articles
Accepted to BLP at AACL 2025!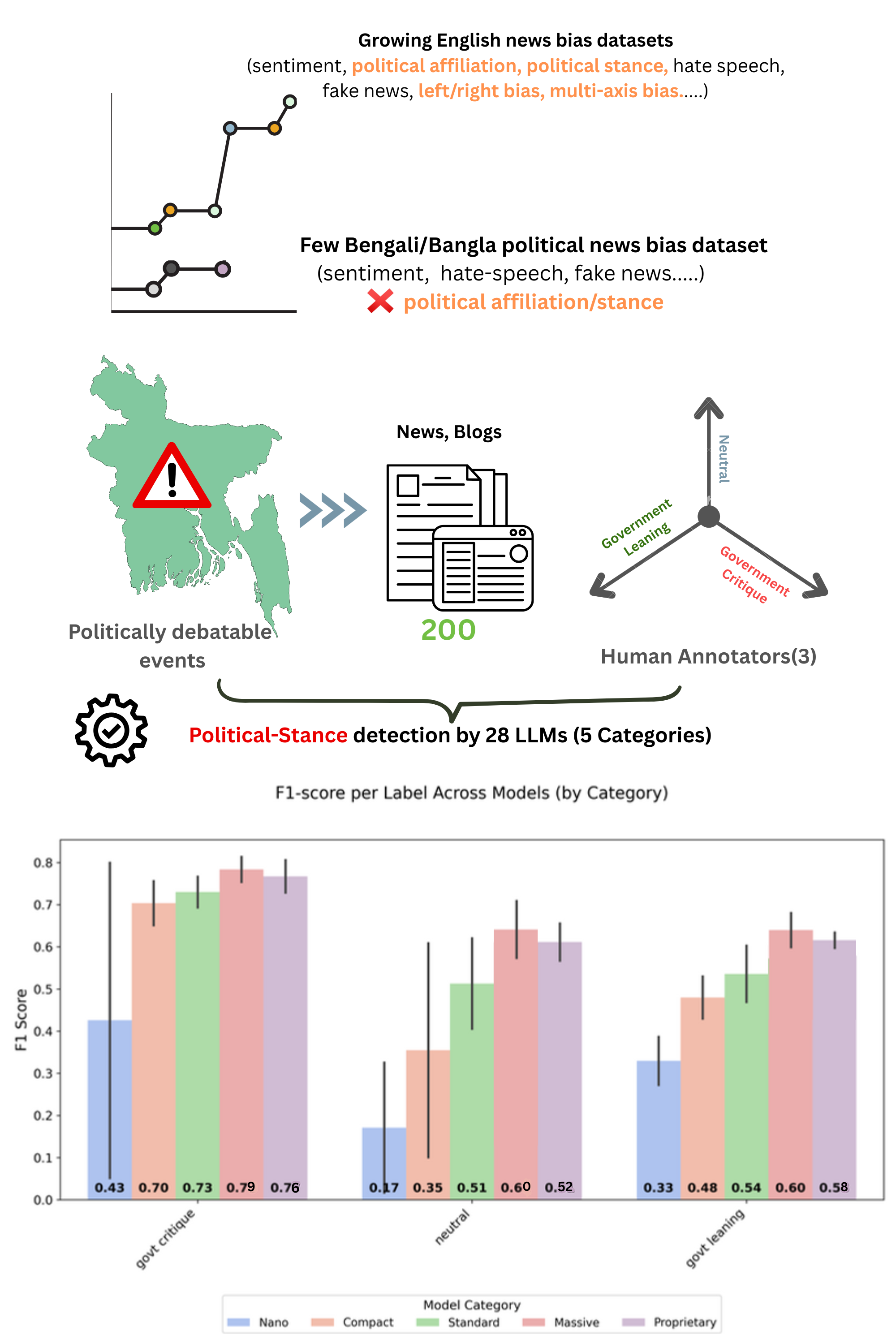
Abstract
Detecting media bias is crucial, specifically in the South Asian region. Despite this, annotated datasets and computational studies for Bangla political bias research remain scarce. Crucially because, political stance detection in Bangla news requires understanding of linguistic cues, cultural context, subtle biases, rhetorical strategies, code-switching, implicit sentiment, and socio-political background.
To address this, we introduce the first benchmark dataset of 200 politically significant and highly debated Bangla news articles, labeled for government-leaning, government-critique, and neutral stances, alongside diagnostic analyses for evaluating large language models (LLMs). Our comprehensive evaluation of 28 proprietary and open-source LLMs shows strong performance in detecting government-critique content (F1 up to 0.83) but substantial difficulty with neutral articles (F1 as low as 0.00). Models also tend to over-predict government-leaning stances, often misinterpreting ambiguous narratives. This dataset and its associated diagnostics provide a foundation for advancing stance detection in Bangla media research and offer insights for improving LLM performance in low-resource languages.
Loading leaderboard...
Analysis Visualizations
Detailed performance metrics and bias analysis
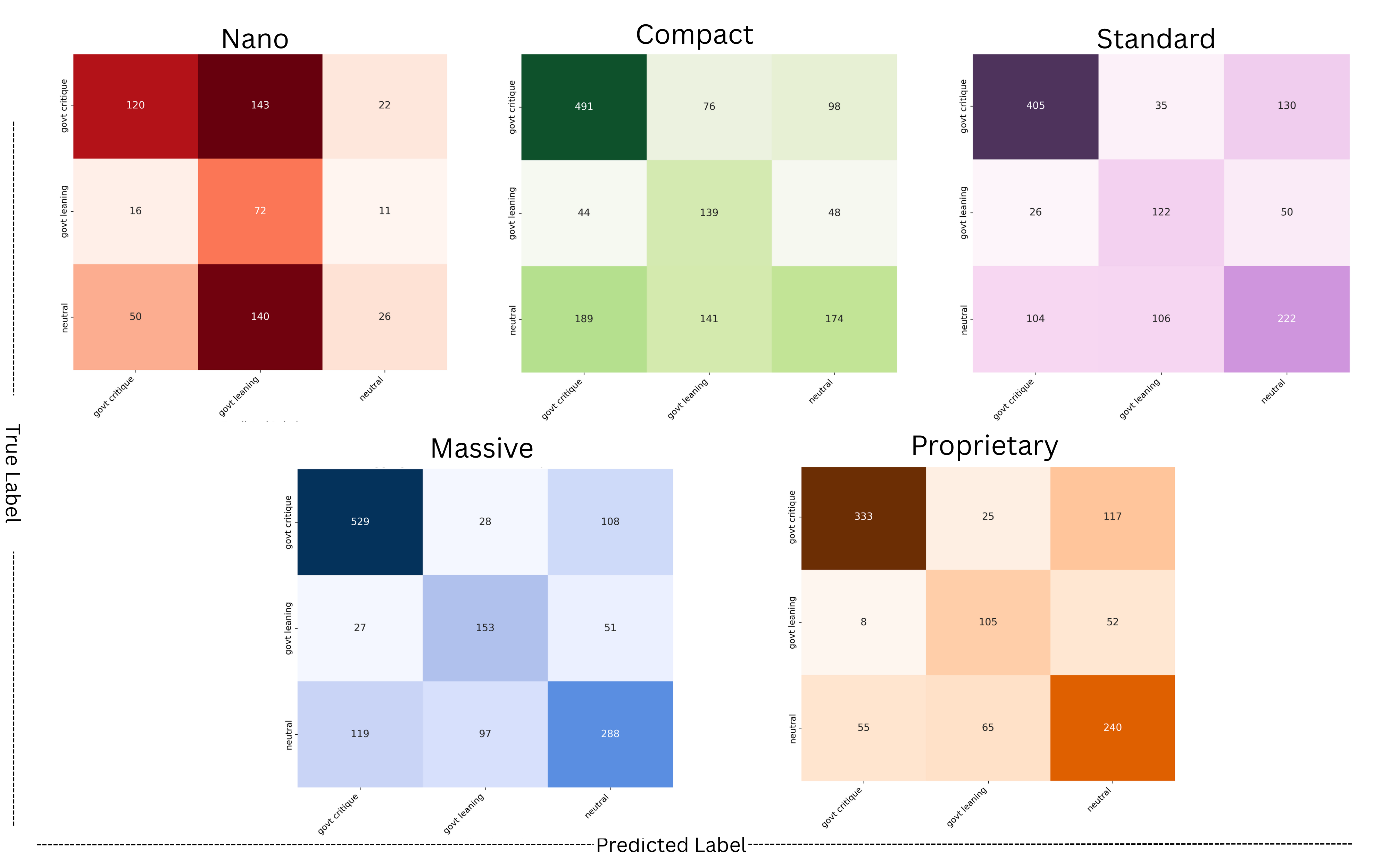
Confusion Matrix
Confusion matrix across all evaluated models.
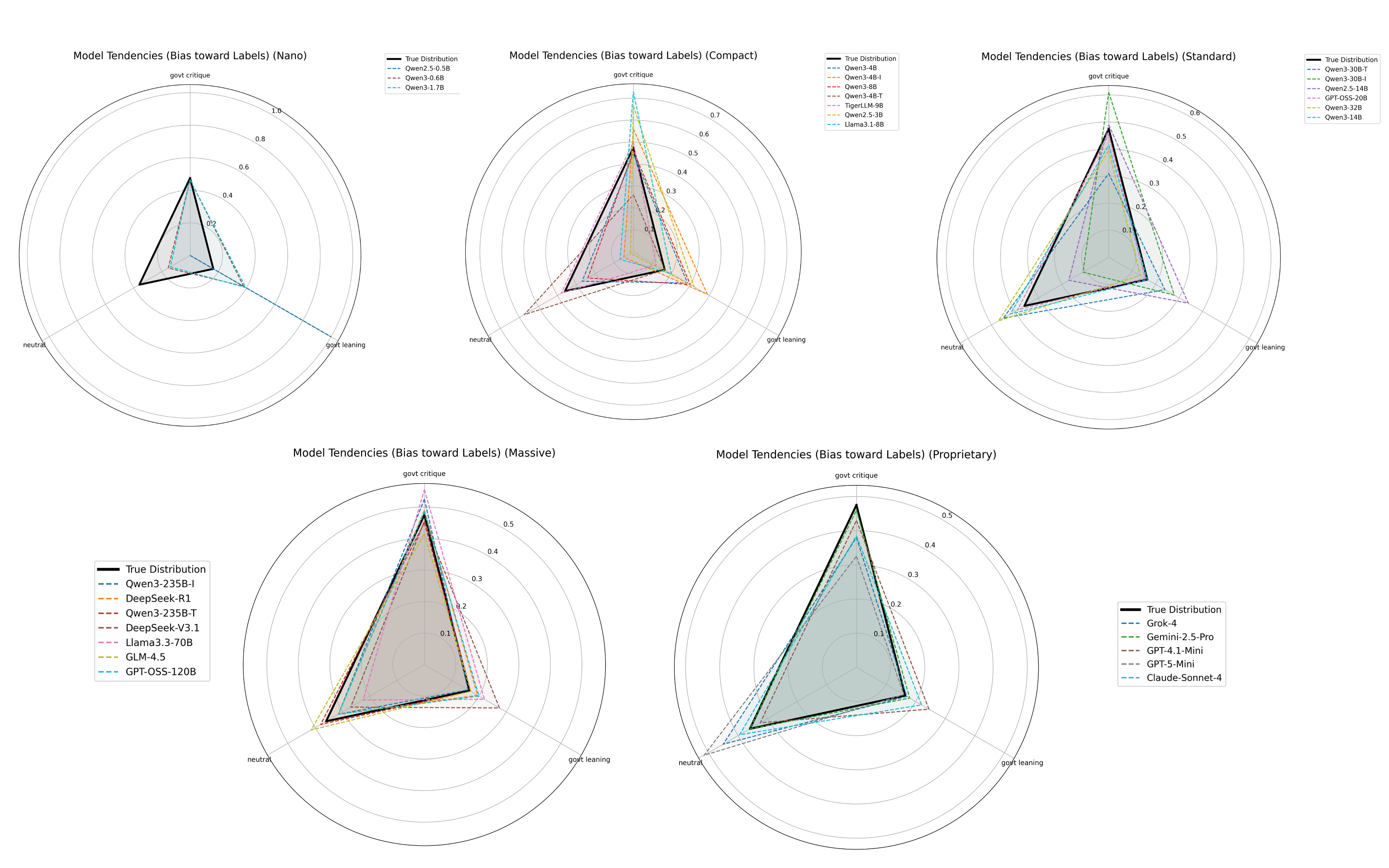
Bias Tendency Analysis
Distribution of model predictions across the three bias categories.
Citation
@article{lia2025read,
title={Read Between the Lines: A Benchmark for Uncovering Political Bias in Bangla News Articles},
author={Lia, Nusrat Jahan and Dipta, Shubhashis Roy and Zehady, Abdullah Khan and Islam, Naymul and Chakraborty, Madhusodan and Wasif, Abdullah Al},
journal={arXiv preprint arXiv:2510.03898},
year={2025}
}